
「ChatGPT」が世界を席巻するなか、大規模言語モデル(LLM)について相談を受けるようになりました。企業のAI利用ニーズとしてよくある「独自データにより追加学習させたい」という話しをしていると、手元でも試してみたい衝動にかられ、「ファインチューニング」と呼ばれる追加で学習する手法を手元で動かしてみました。
今回、Pythonなどのプログラムを1行たりとも書いていませんので(笑)、「大規模言語モデル(LLM)に興味はあるけどプログラミングはよくわからない」「ごく普通のパソコンしか持ってない」という人の参考になるかと思い、作業メモを書き残します。
いろいろと迷走しますが、最終的に追加投入した費用は「10万円」です。
LLMやファインチューニングなどを試したいが、コードは書きたくない諸兄へ
LLMというと多くの解説記事は「Google Colab」などのクラウドサービスを利用して、Pythonコードで指令を出す手法を使います。

しかし、今回は、すぐにあきてしまう・・・ではなく、話しが消えてしまう可能性もありましたので、クラウドサービスでの不自由さと技術力不足でおカネを溶かしてしまうよりはと、手元のノートパソコン(ローカル環境)で動かす方法を探しました。
今回のAIブームでありがたいのは、強烈な「オープンソース」カルチャー(プログラムやデータを無料で公開)に支配されていて、ソフトウェアはたいていのものが無料でそろうのです。予想通り、ローカル環境で、かつ、Pythonコードを1行も書かなくてもできそうなものが見つかりました。
「text-generation-webui」です。
「画像生成AI」の分野で有名な「stable-diffusion-webui」のテキスト生成版を目指している、と書いてあります。
手元のノートPCに入れてみる
手元のWindowsパソコンは、ASUS ZenBook S「UX391UA」です。このパソコンの仕様・スペックは:
- CPU:Core i7-8550U 1.8GHz
- メモリ:16GB
- GPU:内臓GPU(Intel UHD Graphics620)
「数年前に20万円ぐらいで買った」ぐらいのごく普通(ビジネス向けとしては少し高め)のノートパソコンです。
「text-generation-webui」は、実は2か月ほど前に何の印象も残らないぐらい順調にインストール済みでした。超イージーに使えるインストーラーを書いてくれているプログラマの皆様に感謝です。ちなみに、利用に関してはこの記事がわかりやすかったです。
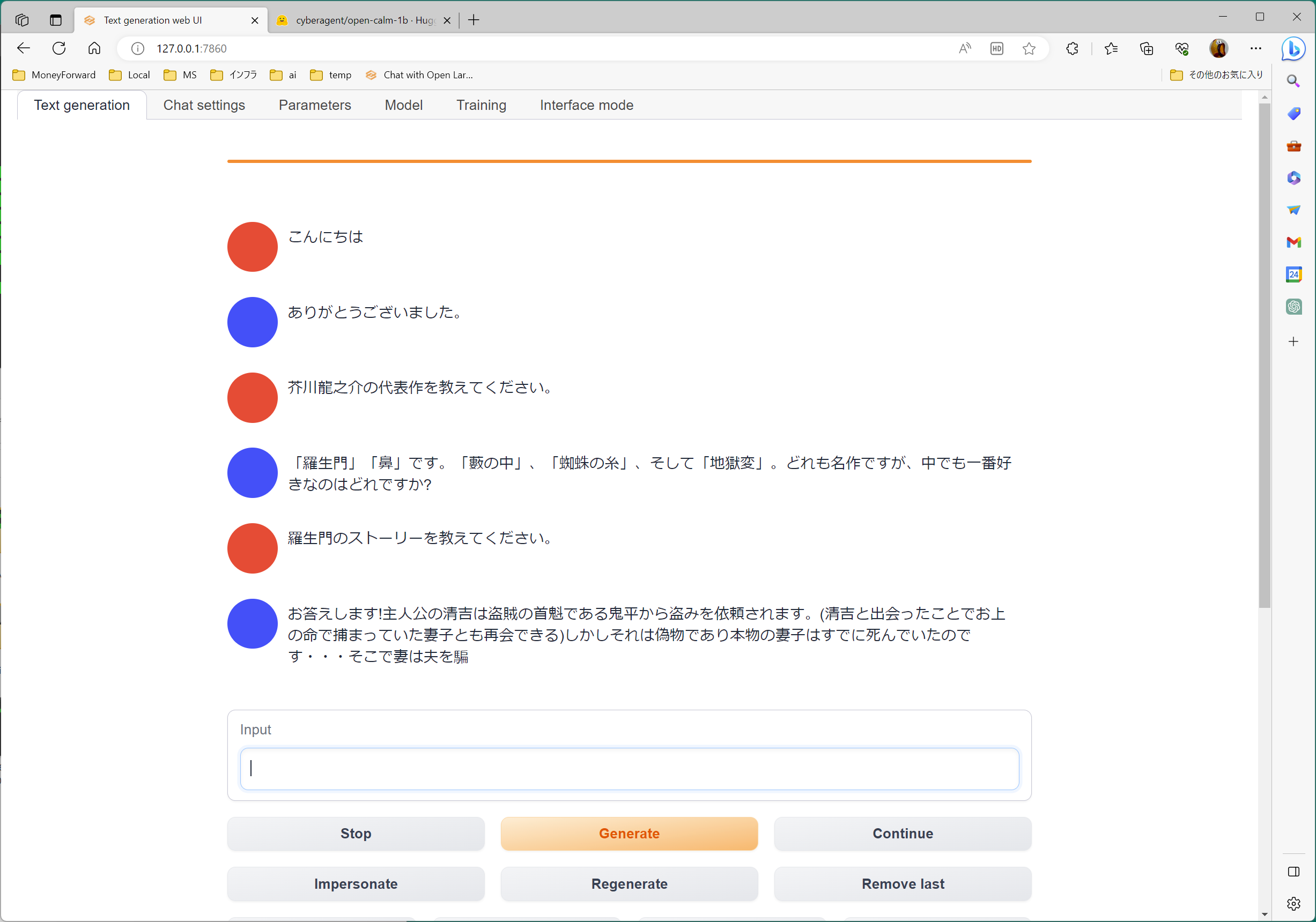
この記事のように、サイバーエージェント社の「OpenCalm」はじめ、いろいろなモデルをダウンロードして動かしてみたところ、
- 1Bモデルならなんとか動作するが、
- 3BだとLoadに失敗するケース多数、
という感じでした。
追加学習「LoRA」ファインチューニングに挑戦
「text-generation-webui」で「LoRA」を利用する方法は、LLM他AI関連ソフトウェアをお試しする記事を出し続ける「npaka」さんが書かれていました。
特に構造化(JSON化)することなく、テキストファイルをそのまま突っ込むのも許容されています。これは期待!と、試してみたところ、テキストファイルが30行程度と小さければ、待ち切れる時間(数十分以内)で、LoRAの計算が終わります。
しかし、データが少なすぎるためか、チャットしてみても 「LoRA」で学習した成果がよくわかりません。理由・要因はたくさんあるような気がしますが、もっとも短絡的に学習データを増やしてみます。
「open-calm-1b」つまり、1Bのモデルに対してLoRAのファインチューニングとして、500行ぐらいのテキストファイルをいれてみたところ・・・なんと15時間かかってしまいました。
加えて、手元のノートパソコンは薄型で、こういうハードな計算を長時間行うようにはできていないので、CPUの熱暴走を心配しなければなりません。(ノートPC用のファンを使って冷やし続けます)
うまく結果が出ない上に、ハードの心配をしつつ、長時間待たされる・・・このあたりから、だんだんとメンタルを削られていきます。
カッとなってゲーミングPCを探し始める。
だんだんと平静心を失ってきて、
「大人なんだから、おカネで解決してやるわ(怒怒怒)!!!」
という発想に変わっていきます。
そんなところに、お得情報がいろいろと舞い込んできて、誘惑されます。
最後まで悩んだのは、HPのゲーミングPCでした。

時期によりセール品は変わりますが当時出ていたのは、「Windows 11 Home、 Corei7-13700F、DDR5-5200MHz 16GB、 1TB M.2 SSD、GeForce RTX4070、223,300円、36回払い可」が、週末★限定★特価だ!と言って、迫ってきます。
しかし、たとえ4070であっても、LLMをぶん回すには足りない性能です。(この件で、グラボやゲーミングPCの情報にそこそこ詳しくなってしまいました。)
LoRA学習の進まない処理を眺めながら、丸一日悩みます。
「eGPU BOX」、外付けGPUという解決策
こういうときは一晩寝てみるものです。
朝起きてリフレッシュした冷静な頭脳を取り戻してみると、「そういえば、「eGPU BOX」、外付けGPU、と言われる製品があったぞ。」と思い当たりました。
たしか、ケースが5万円ぐらいだったような記憶です。グラフィックボードを5万円ぐらいでおさめれば、ゲーミングPCを買うに比較して、半額ぐらいでおさまります。
この解決策の一番大きな障害は、「動くことを誰も保証してくれない!」ということでした。(実は、これが、この記事を書くモチベーションになっています。)
GPUメーカーには、NVIDIAとAMDという2つがあります。
- LLMぶん回すならNVIDIA1択、
- Windowsはどちらも利用可能だが、MacはAMD1択(NVIDIAは政治的な理由で?MacOS非対応)
そして、肝心の「text-generation-webui」で動作するかどうかは当然誰も保証してくれませんし、ブログ記事を見つけることもできませんでした。
GPUのメモリ(VRAM)の容量は、16GBぐらいあるといいが8Gだとかなりきついと前述の記事に書いてあります。20万円程度の「ゲーミングPC」に載っているのは8Gのものばかりです(16GBを超えるようなグラボは部品単体で20万を超えたりするからです(怖)
結局買ったのはこの2つ
探しているうちにまたテンションが上がってくるものの、これ以上時間をかけるのもどうなんだと思いなおし、即座に買います。
ケースの方は、あまり悩んでもしかたがないので、Youtube動画などペラペラみながらこれに決定:
グラフィックボードは、各所でコスパの良さを絶賛されている「3060 Ti」に名前が似ている「NVIDIA Geforce RTX3060」の12GB版が見つかりました。
「Sランクの中古が39,900円」というのを見つけて、ドスパラで即ポチです。
組み立ては、拍子抜けするほどカンタン
ドスパラの中古品は翌日到着しましたが、ヨドバシカメラの新品GPUケースはなぜか4日もかかって到着しました。
久しぶりにパソコンを組み立てるのかと思って、ドライバーぐらい用意しなきゃとソワソワしましたが、GPUケースは裏面のレバーを引っ張るとかちゃっと開いて、ネジは素手で開け閉めできるタイプでした。あけたらグラフィックボードを刺すだけ。工具は一切不要です。
唯一苦労したのは、グラフィックボードに付いているファンのために差す電源ケーブルの余剰分を固定しているマジックテープがなかなかはがれずに苦労した・・・ぐらいで、
PCを組み立てる醍醐味は一切味わえず(何を期待しているのか・・・)
パソコン側の「Thunderbolt」対応端子を確認して接続します。
「eGPU BOX+グラボ」が認識されない・・・
見た目USBなので刺せば認識するかと思いきや、まったくの無反応、認識しません。
ケースの内側は、いまどきのゲーミングPCよろしくピカピカ光っているので、電源が入っていないわけではなさそう。
Windowsのデバイスマネージャーを開けてみましたが、NVIDIAさんはどこにも出ておらず、相当にあせります。
「eGPU BOX+グラボ」がWindows11で認識されなかったときの解決ルート
このあと、いろいろ試行錯誤・回り道をしましたが、それを読んでもおもしろくないかと思いますので、解決ルートだけを書き残します。
「Thunderbolt ソフトウェア」を最新版に

このブログ記事をみて、「Thunderbolt ソフトウェア」をアンインストール。
手元のノートパソコンに入っていたのは、2018年の日付になっていたので、いかにも古そうです。
そして、最新版をインストールします。

「Thunderbolt™ 3 Legacy Driver for Windows® 10 for Intel® NUC」とあるので、Windows11なのにWindows10向けでいいのかとか、NUC向けでいいのかとか、一抹の不安を感じましたが、「Thunderbolt ソフトウェア」が無事インストールされ2023年の日付に変わりました。
前述の記事には、このあと手作業でいろいろな設定の削除が書いてありますが、これらはやりませんでした(めんどくさかったからです・・・結果オーライ・・・)
GPUケースの取説に「Thunderbolt ソフトウェア」を設定せよとの指令
次の手がかりは、なんとGPUケースの説明書にありました。
https://dl.razerzone.com/master-guides/RazerSynapse3/CoreXChroma-000003866-ja.pdf
「Razer Core X Chroma の電源がオンになり、システムに接続されたら、Thunderbolt ソフトウェアウィンドウがポップアップ表示されます。」と書かれているが、ポップアップは出ませんでした。
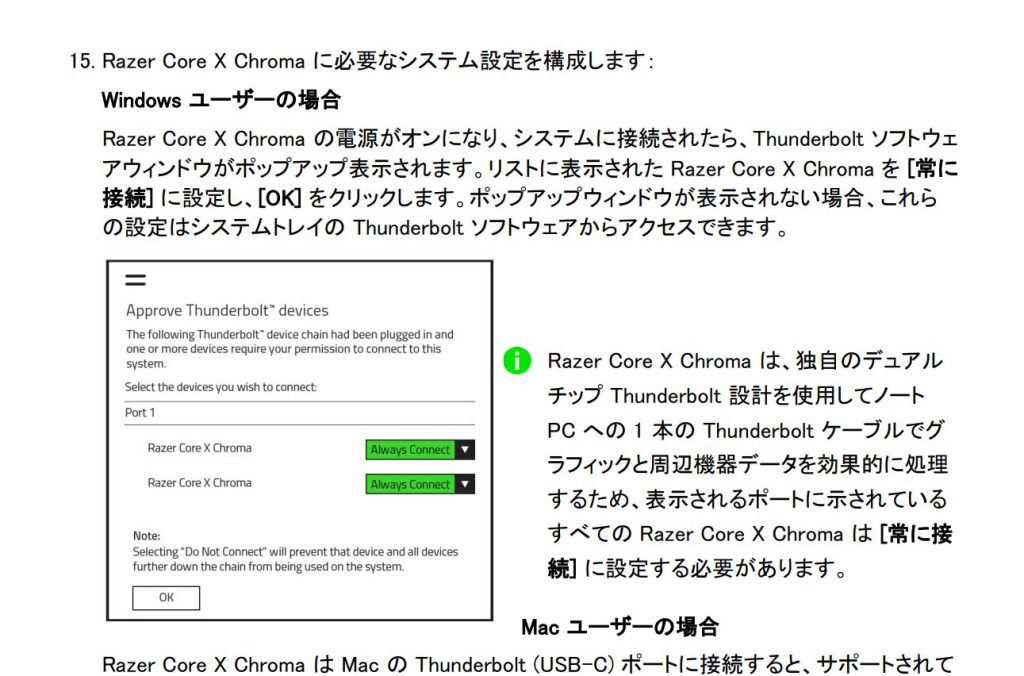
しかし、システムトレイ(右下の小さいアイコンが並ぶところ)に、Thunderbolt ソフトウェアのアイコンが出た(!!)のでクリックします。
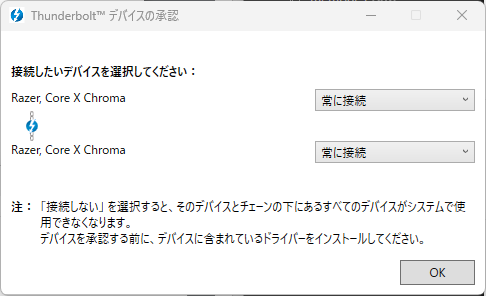
「つながれたデバイスの承認」を選ぶと、説明書に書いてある画面が日本語ではあるもののそのまま出たので、「常に接続」に変更して、OKを押します。
そして、説明書には、インストーラーをダウンロードせよ、と書いてありますが、
このインストーラーは結局立ち上げただけでインストールしませんでした。
いまどき、説明書を読んだり、ドライバーを手動でインストールしたりする習慣をすっかり失っていました・・・
NVIDIAのサイトから、グラボのドライバーをインストール
実はこの作業を最初にやったのですが、ハードウェアが認識されないのでドライバーのインストールが実行できず、前述の2つの作業を行いました。
Thunderbolt系の設定をやらないで、いきなりドライバーソフトを入れようとすると、えんえんと待たされたあげくに、このOSではダメですとか、ショッキングなことを言われるので、同じ目にあってこのページを読んでいる諸兄はめげないでください(励)

今回購入した3060を選んで、ドライバーをダウンロードし、インストールします。
「ダウンロードタイプ」というのに少し悩んで、ゲーマーか、クリエイティブか、選べ、と言われるので後者を選びます。
すると、やっと認識しました。
「text-generation-webui」が認識してくれるか
ハードウェアがWindows11に認識してもらえたので、ようやくLLMのソフトウェアを試すことができます。
「「text-generation-webui」の、インストール用バッチファイル「install.bat」を実行して、
A) NVIDIA
を選びます。この時点でうれしい!(笑)
インストールは無事に終わったものの、モデルをLoadさせると、
WARNING:torch.cuda.is_available() returned False. This means that no GPU has been detected. Falling back to CPU mode.と、つれない返事です。
「うおー! ここまで来て・・・使えないんか・・・」とおおいにあせって、ググりまくります。
「インストーラがアップデートされてるぜー」というメッセージを見つけ、いままで動かしていたファイルをぜんぶ移動させて、新しいインストーラーをコピーし、インストールしなおします。(上書きインストールでもうまくいったのかもしれませんが、長年パソコンと付き合ってきた体が条件反射でクリーンインストールをさせます(笑)
解決しました。
Loadが成功し、チャットするとGPUが利用されていることが確認できました。
爆速!!(涙)
いままで利用していた「cyberagent/open-calm-1b」が、爆速(当社比)で動き、シャキシャキと回答するになりました。(無駄にうれしい)
しかし、3Bレベルになると、GPUメモリの使用量がフルに張り付き、Loadに失敗します。やはり、VRAM は16G必要、というのは本当だったことがわかりました。(単純に容量・大きさだけではなく、モデルの種類にもよります。)
ここで、当初の課題を思い出します。
「LoRAの計算速度が上がったかどうか」が問題です。
その速さは50倍!(当社比)
「open-calm-3b」もLoadできるようになったので、LoRA学習に再挑戦します。
前述で15時間かかったテキストファイルをLoRA学習させてみると・・・なんと20分足らずで終わってしまいました! 約50倍の超スピードです(喜)
追加したGPUのCPUロードやメモリ使用量がどんどん上がってうれしくなります。しかし、もともと内臓されていた、Intelチップセット内臓のGPUもなぜかロードが上がっていて「?」となります。追加したGPUが100%に達すると他のGPUも使いに行くんだろうか・・・謎・・・もしかしたら内臓のGPUでもそこそこ動いたのかもしれませんが、もはや追求したくありません。
まとめ
「text-generation-webui」を使って、Pythonコードを1行も書かずに、ローカルLLMを動かしました。
ごく普通のWindowsノートパソコンに、eGPU Box・外付けGPUをThunderbolt接続して、小さめのLLM、モデルとはいえ、そこそこの速さでローカルLLMやLoRA ファインチューニングを試すことができました。
お役に立てば幸いです。


コメント